+ Với thuật toán sắp chọn: nội dung của mảng a sau khi vòng lặp ngoài đã lặp được N/4 lần ( bắt đầu bằng một phép xáo trộn ngẫu nhiên của các số nguyên từ 1 đến N coi như dữ liệu nhập cần sắp); procedure selection; var i, j, min, t: integer; begin for i:=1 to N-1 do begin min:=i; for j:=i+1 toN do if a[j] then min:=j; t:=a[min]; a[min]:= a[i]; a[i]:=t end; end; 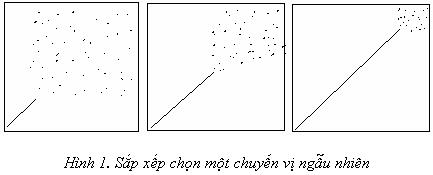
+ Với thuật toán sắp xếp chèn: nội dung của mảng a sau khi vòng lặp ngoài đã lặp được N/2 lần; procedure insertion; var i,j,v: integer; begin for i:= 2 to N do begin v:= a[i]; j:=i; while a[j-1]>v do begin a[j]:=a[j-1]; j:= j-1 end; a[j]:= v end end;  + Với thuật toán sắp xếp nổi bọt: nội dung của mảng a sau khi vòng lặp ngoài đã lặp được 3N/4 lần ; Procedure bubble; var i, j, t: integer; begin for i:= N downto 1 do for j:= 2 to i do if a[j-1]> a[j] then begin t:= a[j-1]; a[j-1]:=a[j]; a[j]:=t end end; 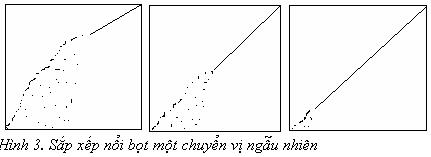 Trong các hình vẽ, một hình vuông được đặt ở vị trí (i, j) với a[i]=j. Một mảng không có thứ tự vì vậy sẽ là sự hiển thị ngẫu nhiên của các hình vuông; trong một mảng đã được sắp, mỗi hình vuông sẽ xuất hiện ở trên cái nằm bên tay trái của nó. Để cho rõ ràng trong các hình vẽ, ta chỉ ra các phép chuyển vị (các phép sắp xếp lại của các số nguyên từ 1 đến N), mà khi đã được sắp, sẽ có các hình vuông tất cả đều thẳng hàng dọc theo đường chéo chính. Các hình vẽ cho thấy các phương pháp khác nhau đã tiến triển hướng về mục tiêu này như thế nào. Hình 1 minh hoạ làm thế nào phép sắp xếp chọn chuyển từ trái sang phải, đặt các phần tử vào vị trí kết quả của chúng mà không nhìn ngược lại. Điều không rõ ràng trong đồ hình này là sắp xếp chọn tốn thời gian để tìm phần tử nhỏ nhất trong phần chưa sắp của mảng. Hình 2 trình bày cách thức phương pháp chèn đi từ trái qua phải, chèn các phần tử mới phát hiện vào đúng chỗ mà không cần quan sát gì thêm ở phía trước. Phía trái của mảng thay đổi liên tục. Hình 3 cho thấy sắp xếp chọn và nổi bọt tương tự nhau. Sắp xếp bằng phương pháp nổi bọt “chọn” phần tử lớn nhất trong số còn lại trong mỗi giai đoạn, nhưng không tận dụng được thứ tự để sắp phần còn lại của mảng. Tất cả các phương pháp đều tỉ lệ N2 trong cả hai trường hợp tốt và xấu nhất bà không đòi hỏi nhiều bộ nhớ. Vì vậy các lần so sánh của chúng phụ thuộc vào chiều dài của các vòng lặp trong đặc tính của dữ liệu nhập. * Sắp xếp bằng phương pháp chọn cần N2/2 lần so sánh và N lần hoán vị. Chúng ta có thể thấy rõ được tính chất này khi hình dung ra bảng NxN, trong đó mỗi ký tự tương ứng với một phép so sánh. Nhưng nó chỉ khoảng một nửa các phần tử nằm trên đường chéo. N-1 phần tử trên đường chéo (trừ phần tử cuối), mỗi phần tử tương ứng với một hoán vị. Chính xác hơn: với mọi i từ 1 đến N-1, có một hoán vị và N-1 so sánh, vì thế tổng cộng có N-1 hoán vị và (N-1) + (N-2)+…+2 + 1= N(N-1)/2 so sánh. Dù cho dữ liệu nhập như thế nào đi nữa thì kết quả trên vẫn giữ nguyên: phần duy nhất của phương pháp sắp xếp chọn phụ thuộc vào việc nhập là số lần giá trị min được cập nhật. Trong trường hợp xấu nhất, các thuật toán cũng tỉ lệ N2, nhưng trong trường hợp trung bình, tính toán này tỉ lệ với NlogN vì thế chúng ta mong muốn là thời gian chạy phương pháp sắp bằng chọn sẽ không bị ảnh hưởng bởi dữ liệu nhập. * Sắp xếp bằng phương pháp chèn trung bình cần N2/4 lần so sánh và N2/8 lần hoán vị, vấu nhất gấp đôi số lần này. Thử cài đặt phương pháp chèn chúng ta sẽ thấy: số lần so sánh và “hoán vị một nửa” (di chuyển) ngang nhau. Việc tính toán này dễ quan sát hơn khi sử dụng bảng NxN, nó thể hiện rõ chi tiết của thao tác của thuật toán chèn. Số phần tử bên dưới đường chéo chính đếm được là các phần tử trong trường hợp xấu nhất. Trong trường hợp dữ liệu nhập là ngẫu nhiên, chúng ta mong muốn mỗi phần tử dời ngược nửa đường tính theo trung bình, là khoảng nửa số phần tử nằm dưới đường chéo chính. * Sắp bằng phương pháp nổi bọt cần trung bình N2/2 lần so sánh và N2/2 hoán vị và tương tự cho trường hợp xấu nhất. Trong trường hợp xấu nhất (tập tin sắp ngược), rõ ràng là lần sắp xếp nổi bọt thứ i cần (N-i) so sánh và hoán vị, chúng ta có thể chứng minh giống như phương pháp chọn. Nhưng thời gian chạy của phương pháp nổi bọt phụ thuộc vào dữ liệu nhập. Chẳng hạn, chỉ cần một lần lặp khi tập tin đã sắp rồi (trường hợp này phương pháp chèn cũng nhanh như vậy). Trường hợp trung bình không tốt hơn bao nhiêu so với trường hợp xấu nhất mặc dù việc phân tích có vẻ phức tạp hơn. * Sắp xếp bằng phương pháp chèn là tuyến tính đối với các tập tin “hầu như đã được sắp”. Mặc dù quan điểm về tập tin “hầu như đã được sắp” là khá không chính xác, nhưng sắp bằng phương pháp chèn thao tác tốt trên một số kiểu tập tin không ngẫu nhiên thường có trong thực tế; thực ra sắp bằng phương pháp chèn đã lợi dụng được thứ tự hiện có trong tập tin. Chẳng hạn, để ý thao tác trong sắp xếp bằng phương pháp chèn trên tập tin đã sắp. Mỗi phần tử sẽ được xác nhận ngay vị trí thích hợp của nó trên tập tin, và tổng thời gian thực hiện thì tuyến tính. Tương tự cho sắp xếp bằng phương pháp nổi bọt, nhưng sắp bằng phương pháp chọn vẫn tỉ lệ N2. Mặc dù tập tin không được sắp hoàn toàn, nhưng sắp bằng phương pháp chèn có thể rất có ích vì thời gian chạy phụ thuộc mạnh vào thứ tự hiện có trong tập tin. Thời gian chạy phụ thuộc vào số lần hoán chuyển: với mỗi phần tử, đếm số phần tử nằm bên trái lớn hơn nó. Đó là khoảng cách mà các phần tử cần dời đổi khi chèn vào tập tin trong quá trình sắp xếp. Tập tin có sẵn các phần có thứ tự thì ít phải chuyển đổi hơn. Giả sử khi muốn thêm vài phần tử vào một tập tin đã sắp để tạo một tập tin lớn hơn có thứ tự. Một cách để làm điều này là thêm các phần tử mới vào cuối tập tin sau đó gọi một thuật toán sắp xếp. Rõ ràng là số lần hoán chuyển sẽ thấp trên tập tin này: một tập tin có một số không đổi các phần tử chưa đặt đúng chỗ sẽ chỉ dùng một số lần hoán chuyển tuyến tính. Một ví dụ khác là tập tin trong đó mỗi phần tử cách vị trí cuối cùng của nó (vị trí kết quả) một khoảng không đổi. Các tập tin như vậy có thể được tạo trong các bước khởi tạo của một vài thuật toán sắp xếp cải tiến: theo một quan điểm nào đó thì nó cũng chính là một dạng của sắp xếp bằng phương pháp chèn. Để so sánh thêm giữa các phương pháp, người ta cần phân tích chi phí của các phép so sánh và hoán vị, một yếu tố phụ thuộc vào kích thước của cá mẩu tin và khoá. Chẳng hạn, nếu mẩu tin là các khoá lưu một từ (word) thì một hoán vị (hai lần truy xuất mảng) sẽ tốn hai lần so với so sánh. Trong tình huống này, thời gian chạy của sắp bằng phương pháp chọn và phương pháp chèn có thể so sánh sơ lược, nhưng sắp bằng phương pháp nổi bọt thì chậm hơn hai lần (thường phương pháp này chậm hơn hai lần trong mọi trường hợp!). Nhưng nếu các mẩu tin cần nhiều so sánh trên khoá, phương pháp sắp xếp chọn sẽ tốt hơn. * Sắp xếp bằng phương pháp chọn là tuyến tính đối với các tập tin có mẩu tin kích thước lớn và khoá kích thước nhỏ. Giả sử chi phí cho một lần so sánh là một đơn vị thời gian và chi phí cho một lần hoán vị là M đơn vị thưòi gian (ví dụ như trường hợp ứng với các mẫu tin M từ và khoá 1 từ. Lúc này, sắp xếp bằng phương pháp chèn cần N2lần so sánh và NM lần hoán vị để sắp một tập tin có kích thước NM. Nếu N tỉ lệ với M, số lượng dữ liệu là tuyến tính.
School@net (Theo THNT)
|



