II. Hướng giải quyết bài toán tìm kiếm:
Trong tìm kiếm chúng ta thấy có rất nhiều trương trình được dùng thường xuyên và rộng rãi. Vì vậy sẽ rất có ích khi nghiên cứu chi tiết nhiều phương pháp khác nhau.
Cách
tốt nhất để suy nghĩ các thuật toán tìm kiếm là đưa ra các thao tác tổng quát
được rút ra từ các cài đặt cụ thể, sao cho các cài đặt khác nhau có thể được
thay thế dễ dàng. Các thao tác đó gồm:
- Khởi tạo cấu trúc dữ liệu (INITIALIZE)
- Tìm kiếm một hay nhiều mẩu tin có khoá đã cho (SEARCH)
- Chèn thêm một mẩu tin mới ( INSERT)
- Nối lại từ điển để tạo thành một từ điển lớn hơn.(JOIN)
- Sắp xếp từ điển; xuất ra tất các mẩu tin theo thứ tự được sắp xếp (SORT)
Trong
một vài trường hợp, các thao tác này được tổ hợp thành một thao tác phức tạp hơn. Ví dụ như thao tác SEARCH_INSERT (tìm kiếm và chèn). Thao tác này thường được dùng trong các trường hợp các mẩu tin với khoá bằng nhau không được phép lưu trữ trong cấu trúc dữ liệu. Trong nhiều phương pháp, mỗi lần xác định một khoá nào đó không có trong cấu trúc dữ liệu thì trạng thái của thủ tục tìm
kiếm sẽ chứa chính xác thông tin cần thiết để chèn thêm một mẩu tin mới với khoá đã cho.
- Một trong 5 thao tác liệt kê trên đều có những ứng dụng rất quan
trọng và một số lớn những tổ chức dữ liệu cơ sở đã được đề nghị để dùng phối hợp các thao tác trên một cách hiệu quả. Chúng ta sẽ xét cụ thể cách cài đặt của hàm cơ bản SEARCH và INSERT…
1. PHƯƠNG PHĂP TÌM KIẾM TUẤN TỰ
a. Tìm kiếm tuần tự cài đặt mảng
Đây là một trong những phương pháp tìm kiếm đơn giản và dễ thực hiện nhất đặc biệt đối với các thông tin được lưu trữ kiểu mảng. Tìm kiếm tuần tự là tìm kiếm và lưu trữ các mẩu tin trong một mảng, sau đó duyệt toàn bộ mảng một cách tuần tự. Mỗi lần tìm và duyệt như vậy ta sẽ tìm thấy được một mẩu tin. Đoạn chương trình đơn giản mô tả thuật toán tìm kiếm tuần tự như sau:
Type diem = record
key, infor: integer;
end;
var A: array[1..maxN] of diem;
N: integer;
procedure intialze;
begin N:=0;
end;
function seqsearch(v: integer; x : integer): integer;
begin
A[N+1].key:=v;
If x then
repeat x:= x+ 1
until v = A[x].key;
seqsearch:= x;
end;
end;
function seqinsert(v : integer): integer;
begin
N:= N + 1;
A[N].key:= v;
seqinsert := N;
end
end;
Đoạn mã trên xử lý các mẩu tin có các khoá (key) và “thông tin đi kèm” có giá trị nguyên (infor). Nhiều ứng dụng cần mở rộng các chương trình để làm việc các mẩu tin và khoá phức tạp hơn, nhưng điều này sẽ không làm thay đổi nhiều các thuật toán.
Ví dụ: trường Infor có thể thay đổi thành con trỏ đến một cấu trúc mẩu tin phức tạp. Trường hợp như vậy, trường infor có thể có thể xem như một chỉ danh duy nhất của mẩu tin để phân biệt những mẩu tin có khoá bằng nhau.
Thủ tục seqsearch có hai đối số: một là giá trị khoá (v), một là chỉ số của mảng (biến x). Chỉ số x này dùng để xử lý trường hợp nhiều mẩu tin có cùng một giá trị khoá. Bằng cách thực hiện liên tục m:= seqsearch(v, m) khởi đầu với m:= 0; chúng ta có thể cho m lần lượt chỉ số của các mẩu tin có khoá bằng v.
Một mẩu tin đặc biệt có khoá là khoá đang tìm được thêm vào; nó bảo đảm rằng quá trình tìm kiếm sẽ kết thúc và cũng làm đơn giản hơn phép kiểm tra trong vòng lặp. Sau khi vòng lặp dừng, nếu chỉ số trả về nhỏ hơn hay bằng N thì đó chính là chỉ số của mẩu tin tìm được. Nếu ngược lại thì trong bảng đã cho không có mẩu tin có giá trị khoá muốn tìm. Kỹ thuật này giống như kỹ thuật dùng một mẩu tin chứa giá trị khoá nhỏ nhất hay lớn nhất để làm đơn giản các vòng lặp của các thuật toán trong các chương trình sắp xếp.
Ta có thể rút ra một kết luận cho thuật toán tìm kiếm tuần tự như sau:
Tìm kiếm tuần tự (cài đặt mảng) sử dụng đúng (N +1) phép so sánh cho một lần tìm kiếm không thành công và trung bình có khoảng N/2 phép toán so sánh cho một lần tìm kiếm thành công.
Trường hợp tìm kiếm thành công, điều này là hiển nhiên được thấy ngay trong đoạn chương trình trên.
Trường hợp tìm kiếm không thành công, chúng ta giả sử rằng mỗi mẩu tin có khả năng tìm thấy là như nhau, thì số trung bình của số lần so sánh sẽ là:
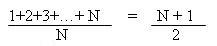
Con số này bằng đúng bằng đúng một nửa của trường hợp tìm kiếm không thành công.
Ngoài phương pháp cài đặt bằng mảng như thuật toán trên, TÌM KIẾM TUẦN TỰ có thể được cài đặt bằng một phương pháp sử dụng một xâu liên kết để biểu diễn cá mẩu tin như:
b. Tìm kiếm tuần tự cài đặt bằng xâu có thứ tự
Một trong những thuận lợi của phương pháp này là giữ cho xâu được sắp xếp, và nhờ đó có thể tìm kiếm nhanh hơn.
type lienket = ↑ diem;
diem = record
key, infor :integer;
next : lienket;
end;
var dau , t , x : lienket;
i: integer;
procedure initialize;
begin
new(z);
z↑.next:= z;
new(dau);
dau↑.next:= z ;
end;
function listsearch(v : integer; t:lienket) : lienket;
begin
z↑.key:= v;
repeat
t:= t↑.next
until v < = t↑.key;
if (v= t↑.key) then
listseach:= t;
else
listseach:= z;
end;
end;
Với một xâu được sắp xếp, một lần tìm kiếm có thể kết thúc không thành công khi một mẩu tin có khoá lớn khoá đang tìm kiếm được tìm thấy. Do đó, về mặt trung bình, chỉ khoảng một nửa các mẩu tin (không phải là tất cả) cần được kiểm tra cho một lần tìm kiếm không thành công. Thứ tự sắp xếp được duy trì dễ dàng tại vị trí mà việc tìm kiếm kết thúc không thành công. Ta xét kỹ thuật sau:
function listsearch(v : integer; t: lienket): lienket;
begin
z↑.key: = v;
while (t↑.next↑.key < v) do
new(x);
x↑.next:= t↑.next;
t↑.next:= x;
x↑.key:= v;
listsearch:= x;
end;
Như chúng ta đã biết, đối với các xâu liên kết, có thể một nút dẫn đầu (dau) và một nút kết thúc z để làm đơn giản chương trình. Vì vậy, lệnh listsearch(v, dau) sẽ đặt một nút mới với khoá v vào trong xâu được trỏ tới bởi trường (next) của (dau). Các lần gọi listsearch kế tiếp dùng các xâu trả về của lần trước đó để đưa ra các mẩu tin có các khoá bằng nhau. Nút kết thúc (z) dùng cho trường hợp thành không công, nghĩa là nếu listsearch trả về z thì sự tìm kiếm không thành công.
Vậy tìm kiếm tuần tự (cài đặt bằng xâu có thứ tự) sử dụng trung bình khoảng N/2 phép so sánh cho cả hai trường hợp tìm kiếm thành công và không thành công.
Xét trường hợp ta tìm kiếm thành công với kỹ thuật trên: điều này ta có thể thấy trực tiếp từ đoạn code trên
Trường hợp không thành công khi tìm kiếm:
Giả sử rằng khả năng tìm kết thúc ở mỗi phần tử trong xâu và nút z là như nhau thì số trung bình của các phép so sánh sẽ là:
1+ 2+ 3+…+ N+ (N+ 1)= (N+ 1)(N+ 2)/2
Chúng ta có thể cải tiến cải tiến thuật toán tìm kiếm bằng cách sắp xếp các mẩu tin một cách thông minh nếu như ta được biết thông tin về tần số truy xuất các mẩu tin.
Một sắp xếp được gọi là “tối ưu” là một mẩu tin được truy xuất thường xuyên nhất ở vị trí đầu tiên, mẩu tin có tần suất truy xuất thường xuyên thứ hai sẽ nằm ở vị trí thứ hai…Kỹ thuật này đặc biệt có hiệu quả trong những trường hợp chỉ có một tập hợp nhỏ các mẩu tin được truy xuất thường xuyên.
Trường hợp ta không có được thông tin về tần suất truy xuất ta vẫn có thể thực hiện một kỹ thuật xấp xỉ đến sắp xếp tối ưu bằng cách tìm kiếm “tự tổ chức” như sau:
Mỗi lần một mẩu tin được truy xuất, thì di chuyển chúng nên vị trí đầu tiên của xâu. Phương pháp này sẽ dễ dàng cài đặt nếu ta dùng xâu liên kết. Tất nhiên thời gian thực hiện của phương pháp phụ thuộc vào sự phân bố của các mẩu tin, rất khó có thể tính trước được trong trường hợp tổng quát. Dù vậy, phương pháp này rất phù hợp trong trường hợp mỗi mẩu tin có khuynh hướng gần những mẩu tin khác.
2. PHƯƠNG PHĂP TÌM KIẾM NHỊ PHÂN
a. Tìm kiếm nhị phân
Chúng ta đã xét phương pháp tìm kiếm tuần tự, cách này đơn giản trong quá trình cài đặt. Song , hạn chế của phương pháp tuần tự là thời gian tìm kiếm sẽ lâu trong trường hợp tập hợp tổng số mẩu tin lớn. Để khắc phục hạn chế này, ta có phương pháp tìm kiếm NHỊ PHÂN.
Nếu tập hợp các mẩu tin lớn thì tổng số thời gian tìm kiếm sẽ được rút ngắn bằng cách dùng một thủ tục tìm kiếm dựa trên sự ứng dụng sơ đồ “chia - để - trị”. Điều này có nghĩa là chúng ta sẽ chia những mẩu tin thành hai phần, xác định xem phần nào chứa khoá. Kế đến tiếp tục công việc cho phần chứa khoá ta vừa tìm được. Lý do mà chúng ta có thể chia đôi và chỉ tìm kiếm trên một nửa các mẩu tin lf do ta đã giả thiết các mẩu tin được sắp xếp theo thứ tự Khoá. Không mất tính tổng quát, ta giả thiết rằng các mẩu tin được sắp xếp theo thứ tự tăng dần(trường hợp sắp xếp giảm dần có thể làm tương tự).
Để tìm một khoá k có trong một dãy số hay không, trước tiên ta so sánh nó với phần tử ở vị trí giữa dãy ký tự. Nếu k nhỏ hơn thì nó chỉ có thể là ở trong một nửa đầu tiên của dãy số. Trường hợp k lớn hơn tức là k nằm trong nửa còn lại của dãy. Chúng ta sẽ tiếp tục áp dụng Đệ quy phương pháp này. Ta có thể gọi Đệ quy một lần mà có thể đưa ra thuật toán dùng phương pháp lặp. Ta hãy cùng xét hàm dưới đây để thấy được thuật toán Nhị Phân thể sẽ thực hiện như thế nào( giả sử rằng: mảng A đã được sắp xếp tăng theo thứ tự Khoá):
function TKnhiphan(k: integer): integer;
var x, l , r : integer;
begin
l:=1;
r:= N;
repeat
x:= (l + r ) div 2;
if (kA[x].key) then
r:= x - 1;
else
r:= x + 1;
until (k = A[x].k) or (l>r);
if (k= A[x].key) then
TKnhiphan:= x;
else TKnhiphan:= N +1;
end;
Như chúng ta thấy trên hàm, thuật toán này đã sử dụng các con trỏ l và r để đánh dấu tập tin con hiện đang làm việc. Mỗi khi vòng lặp thực hiện, biến x nhận giá trị điểm giữa của đoạn hiện hành. Sẽ có ba khả năng sau xảy ra:
- Vòng lặp kết thúc thành công
- Con trỏ trái l thay đổi thành (x + 1)
- Con trỏ phải r được đổi thành (x - 1)
Ba khả năng trên xảy ra tương ứng với giá trị tìm kiếm k bằng, nhỏ hơn hay lớn hơn giá trị khoá của mẩu tin được lưu trữ trong mảng A[x];
Xét 1 ví dụ cụ thể:
Cho 1 dãy ký tự: BBAACDEFFGHMPNHRX
Tìm kiếm M trong dãy ký tự trên bằng phương pháp nhị phân.
Mô phỏng cách thực hiện thuật toán:

thấy rằng, khi tiềm kiếm M trong bảng được xây dựng từ các khoá B A C D E F G H M P N R X, khi đó kích thước đoạn giảm ít nhất một nửa ở mỗi bước. Như vậy, ta chỉ cần dùng tới 4 phép so sánh cho việc tìm được mẩu tin có khóa là M trong ví dụ trên.
Như vậy, số các mẩu tin giảm ít nhất một nửa ở mỗi bước: một cận trên của số các phép so sánh thoả mãn hệ qui nạp Cn = Cn/2 + 1 và C1=1;
Từ nhận xét trên ta rút ra một kết luận: Tìm kiếm nhị phân không bao giờ dùng nhiều hơn (log(N) + 1) phép so sánh.
Chú ý: Điều quan trọng cần lưu ý trong thuật toán tìm kiếm nhị phân này là thao tác chèn thêm một mẩu tin mới chiếm rất nhiều thời gian. Điều này lý giải tại sao mảng luôn phải duy trì trong trạng thái được sắp xếp và một số mẩu tin phải di chuyển đề nhường chỗ cho mẩu tin mới. Nếu một mẩu tin có khóa nhỏ nhất so với tất cả các khoá của các mẩu tin khác trong bảng thì mỗi mẩu tin phải được di chuyển lên trên một vị trí. Một thao tác chèn ngẫu nhiên mất trung bình khoảng N/2 mẩu tin bị di chuyển. Đó là lý do tại sao chúng ta không nên dùng phương pháp này cho các ứng dụng đòi hỏi nhiều thao tác chèn thêm mẩu tin.
Trường hợp các mẩu tin có khoá bằng nhau khi sử dụng thuật toán Tìm kiếm nhị phân phải thật cẩn thận. Vi chỉ số trả về có thể rơi vào giữa một khối các mẩu tin có khoá bằng k, do vậy, phải quét theo cả hai hướng từ chỉ số trả về đó để có thể nhặt ra tất cả các mẩu tin có khóa bằng k. Trường hợp này, thời gian chạy cho việc tìm kiếm gần bằng lg(N) cộng với số mẩu tin được tìm thấy.

 I. Bài toán:
I. Bài toán:

