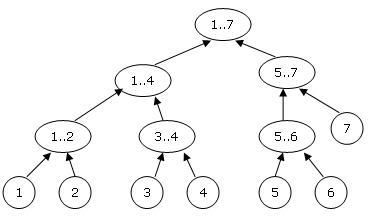
3. Thì Node 2*I lưu đoạn [L..mid] và Node 2*I+1 lưu đoạn [mid+1..R].
Độ cao của interval tree luôn nhỏ hơn hoặc bằng logN. Như vậy bộ nhớ dùng cho interval tree là O(2^(logN+1). Trong thực tế có thể khai báo mảng O(N*3) hoặc O(N*4) là đủ. (Tất nhiên cũng có thể dùng Linklist – danh sách động để lưu interval tree nhưng cách này tốn bộ nhớ hơn và không tiện bằng, không hay được dùng). Nhược điểm của cách lưu này là ta không thể biết được đoạn [L..R] có được lưu trọn trong 1 nút không và nếu có thì nút đó là nút nào mà buộc phải lặp lại 1 quá trình với độ phức tạp O(logN) từ gốc tới đoạn [L..R].
Các thông tin được lưu trong 1 node của interval tree là thông tin tổng hợp của đoạn mà nó quản lý, bởi vậy thông tin này phải là dạng tích luỹ được, ví dụ như tổng, hiệu, min hoặc max,...
Từ sau đây ta gọi chung các thao tác sửa cây Interval là các thao tác UPDATE, các thao tác lấy thông tin từ cây là thao tác GET.
Ứng dụng của cây Interval tree đa dạng, phong phú vô cùng. Sau đây ta sẽ tìm hiểu một số ứng dụng cơ bản và hay gặp nhất. Mỗi ví dụ sẽ mô tả 1 cách sử dụng interval tree tương đối khác nhau và thường gặp trong giải toán.
Ví dụ 1. Các bài toán cơ bản ứng dụng Interval Tree:
a. Cho dãy số, có 1 số yêu cầu thuộc 2 loại thay đổi (tăng/gán lại) giá trị 1 phần tử hoặc tìm min, max các đoạn liên tiếp của dãy số: mỗi nút interval tree sẽ lưu giá trị min/max các phần tử nó quản lý.
b. Cho dãy số, có 1 số yêu cầu gán thuộc 2 loại lại giá trị của 1 phần tử hoặc tìm tổng 1 số phần tử liên tiếp của dãy. Bài toán tương tự như ví dụ.
Ví dụ 2: POSTERS – AMPPZ 2001.
Tóm tắt đề bài: Có N tấm poster chiều cao 1. Theo thứ tự các tấm poster được dán lên 1 đoạn tường cũng có chiều cao 1. Đoạn tường được xây bởi các viên gạch 1*1, đánh số từ trái sang phải bắt đầu từ 1. Các tấm poster sẽ phủ 1 đoạn liên tiếp từ viên gạch Li tới viên gạch Ri, tấm poster được dán sau sẽ phủ lên tấm poster được dán trước. Vì vậy, sau khi dán xong cả N tấm poster thì có thể có những tấm poster không thể được nhìn thấy.
Yêu cầu: Đếm số loại poster khác nhau có thể nhìn thấy được từ ngoài vào.
Input: Dòng đầu ghi N là số tấm poster. Trong N dòng tiếp theo mỗi dòng chứa 2 số Li và Ri thể hiện đầu trái và đầu phải của tấm poster thứ i.
Output: Duy nhất 1 dòng ghi số loại poster có thể nhìn thấy được.
Giới hạn: N<=40000. Li,Ri<=10^9.
Hướng dẫn:
Bài toán có thể phát biểu 1 cách dễ hiểu như sau: Cho dãy số M phần tử, có 1 số thao tác tô màu các phần tử của dãy số. Sau khi kết thúc chuỗi thao tác đếm số màu khác nhau của dãy số trên. Với M nhỏ, ta chỉ cần lưu lại được màu của các phần tử sau đó xem có bao nhiêu màu khác nhau là được. Nhưng nếu xét trong bài toán POSTERS này, thì M của chúng ta sẽ có thể lên tới giá trị 10^9. Do đó, ta phải làm nhỏ lại giá trị này. Bằng cách nào? Nhận xét với 2 ô mà giữa chúng không có đầu mút của tấm poster nào thì chắc chắn màu sắc của chúng giống nhau. Từ đó ta thực hiện trộn tất cả các đầu mút của các đoạn, sắp xếp tăng dần chúng. Thay vì phải xét tất cả các ô (có thể lên tới 10^9 ô) ta chỉ cần xét các ô là đầu mút của các đoạn, số lượng này chỉ khoảng 80000 số, hoàn toàn có thể lưu trữ được. Phương pháp ta vừa áp dụng còn được gọi là phương pháp “Rời rạc hoá”, ứng dụng hiệu quả nhiều trong các bài toán khác nhau, nhất là khi sử dụng các cấu trúc dữ liệu đặc biệt. Ý nghĩa chủ yếu là với 1 đoạn lớn các phần tử giống hệt nhau, không cần xét mọi phần tử mà chỉ xét 1 phần tử đại diện. Sau đây các bạn sẽ còn gặp nhiều bài toán sử dụng phương pháp này.
Trở lại với bài toán của chúng ta, bây giờ phải sửa đổi màu các phần tử trong 1 đoạn liên tiếp. Với giới hạn M còn 80000 ta vẫn không thể làm thô được, mà sẽ dùng interval tree. Vì cuối cùng cần màu của mỗi phần tử nên cây interval được xây dựng phải bảo đảm điều kiện lấy được màu của các phần tử. Có 2 hướng lưu trữ cây interval như sau:
1/ Tại mỗi nút lưu màu chung của các phần tử nó quản lý, khởi tạo là màu 0. Chính xác hơn là mỗi nút lưu màu cuối cùng mà nó được sửa, kèm theo thời gian nó được sửa thành màu đó. Quá trình sửa màu vẫn diễn ra bình thường nhưng kết hợp thêm cập nhật thời gian. Màu của 1 phần tử khi đó là màu của nút quản lý nó mà màu được cập nhật muộn nhất. Dễ thấy giá trị đó đúng là màu của phần tử đang xét. Để lấy màu ta chỉ cần đi từ gốc tới nút chứa duy nhất phần tử đó và chọn màu có thời gian lớn nhất.
2/ Cây Interval lưu không chính xác màu của các nút mà chỉ lưu 1 cách gần đúng. 1 nút lưu màu nếu đó là màu chung của tất cả các phần tử nó quản lý, ngược lại lưu giá trị (-1). Ta sẽ kết hợp quá trình sửa đúng lại màu ch o các phần tử vào trong quá trình cập nhật và lấy giá trị các phần tử. Trong quá trình cập nhật, xét tới nút nào thuộc trong đoạn được tô mới màu thì gán luôn giá trị nút đó bằng màu mới và kết thúc (tương tự như bình thường), những nút cha của nút này được gán giá trị -1 (do màu các nút con của nó không còn giống nhau). Trong quá trình lấy giá trị phần tử, nếu 1 nút cha mang giá trị dương thì nút con sẽ mang giá trị của nút cha thay vì giá trị hiện thời của nó, cập nhật lại màu cần diễn ra trước khi xét tới các nút con của 1 nút.
2 cách lưu trên đều khá đơn giản và dễ hiểu (theo tôi cách đầu tiên dễ hiểu và dễ cài đặt hơn còn cách thứ 2 cần hiểu rõ bản chất và tư duy mạch lạc, nếu không sẽ dễ nhầm lẫn giá trị các nút, nhưng nếu cài tốt sẽ nhanh và đỡ tốn bộ nhớ hơn cách đầu). Bạn nên thử cài lại bài toán theo cả 2 cách đã nêu và chọn cách phù hợp nhất cho mình. Tương tự hãy ứng dụng cây interval vào trường hợp tăng/giảm giá trị và tính tổng 1 số đoạn liên tiếp của dãy số.
Ví dụ 3. MARS Map – Baltic OI 2001.
Trên mặt phẳng toạ độ có N hình chữ nhật, có toạ độ các đỉnh trong khoảng từ 0 tới 30000. Tính diện tích phần mặt phẳng mỗi điểm bị phủ bởi ít nhất 1 hình chữ nhật.
Input: Dòng đầu tiên ghi số N, trong N dòng tiếp theo mỗi dòng ghi 2 cặp số lần lượt là toạ độ điểm trái dưới và phải trên.
Output: Duy nhất 1 số là tổng diện tích phần mặt phẳng bị phủ bởi ít nhất 1 hình chữ nhật.
Giới hạn: N<=10000.
Hướng dẫn:
- Vì các toạ độ đều nguyên, nếu ta chia mặt phẳng thành lưới các ô vuông thì diện tích phần bị phủ bởi các HCN chính là số ô vuông thuộc ít nhất 1 HCN. Như vậy ta chỉ cần đếm với mỗi cột dọc rộng 1 đơn vị có bao nhiêu ô vuông như vậy là được.
- Số ô bị phủ mỗi cột chỉ thay đổi khi các HCN phủ nó thay đổi. Do đó nếu giữa 2 cột i,i+1 không có sự thay đổi về các HCN phủ lên chúng thì số ô vuông bị phủ ở 2 cột này là bằng nhau. Sự thay đổi này chỉ có khi có 1 cạnh của 1 HCN hoàn toàn thuộc trên đường thẳng đứng giữa 2 cột trên.
Từ 2 nhận xét trên ta đi tới thuật toán sau:
- B1: sắp xếp chỉ số vị trí các cạnh thẳng đứng của các HCN theo chiều tăng dần, những cột thuộc giữa 2 chỉ số liên tiếp sẽ có số ô bị phủ bằng nhau, ta chỉ cần đếm lượng này rồi nhân với số lượng cột là được. Do đó chỉ xét 1 cột ngay sau vị trí 1 cạnh là đủ.
- B2: xét các cột từ trái sang phải, nếu lần đầu tiên gặp 1 HCN (gặp cạnh dọc trái của nó) thì thêm đoạn mà nó phủ ở cột tương ứng, nếu đó là cạnh dọc phải của HCN thì loại bỏ đoạn mà nó phủ. Mỗi lần xét 1 cột đếm số lượng ô bị phủ của cột đó.
Ta dùng interval tree cho quá trình này. Bài toán có thể được phát biểu lại như sau: Cho 1 dãy số có N số, có 1 số thao tác là tăng hoặc giảm 1 số phần tử liên tiếp của dãy lên 1 đơn vị, sau mỗi thao tác hỏi dãy số có bao nhiêu số lớn hơn 0. Với giá trị max toạ độ = 30000 thì giá trị N trên có thể lên tới 30000, nếu giá trị này lớn hơn sẽ rất khó khăn trong lưu trữ. Nhưng ta cũng có thể áp dụng phương pháp rời rạc hoá các đoạn liên tiếp giống nhau. Khi đó N lớn nhất chỉ bằng số HCN, tức là 10000 mà thôi, bài toán lúc này khác 1 chút: mỗi phần tử kèm 1 hằng giá trị, tính tổng hằng giá trị các phần tử lớn hơn 0.
Với cách phát biểu này bài toán đã trở nên gần gũi hơn và dễ dàng giải quyết hơn rất nhiều. Chỉ cần lưu kèm mỗi nút cây interval là số lượng phần tử dương nó quản lý. Phần còn lại của bài toán xin nhường cho các bạn tự giải.
Dạng mở rộng của interval tree:
Ta đã thấy được sức mạnh của Interval tree trong xử lý bài toán dãy số. Vậy nếu với 1 bảng số thì sao? Nếu coi dãy số là 1 đoạn thẳng (1 chiều) thì bảng số có thể coi như 1 HCN (2 chiều), có sự mở rộng thêm 1 chiều nữa so với dãy số. Như vậy thì hoàn toàn có thể dùng Interval Tree theo 1 cách nào đó để xử lý các bảng số. Cây Interval Tree khi đó thường được gọi là Interval Tree 2D – Cây interval tree 2 chiều. Nếu như Interval Tree chỉ có 1 cách biểu diễn thông dụng và được dùng (tới 99.9% các bài toán dùng cấu trúc mô tả ở trên) thì lại có tới 2 cách hoàn toàn khác nhau để hiểu và biểu diễn Interval Tree 2D. Vậy thế nào là Interval Tree 2D? Xét ví dụ sau:
Ví dụ 4: MATSUM - Al-Khawarizm 2006
Cho ma trận N*N. Ban đầu tất cả các ô của ma trận đều mang giá trị 0. Các dòng đánh số từ 1 tới N từ trên xuống dưới, các cột được đánh số từ 1 tới N từ trái qua phải. Có 1 trình xử lý gồm 3 thao tác chính trên ma trận:
1. SET x y num : gán giá trị của ô (x,y) giá trị num
2. SUM x1 y1 x2 y2 : Tính và in ra tổng giá trị các ô trong HCN ô trái dưới (x1,y1) và phải trên (x2,y2) (x1<=x2, y1<=y2).
3. END : kết thúc chương trình.
Yêu cầu: viết chương trình đọc vào các lệnh của trình xử lý, tính và đưa ra kết quả của các thao tác SUM.
Giới hạn: N<=1024.
Định nghĩa HCN (x1,x2,y1,y2) là HCN giới hạn bởi 2 hàng x1,x2 và 2 cột y1,y2
Cách 1: Quản lý song song cả 2 chiều:
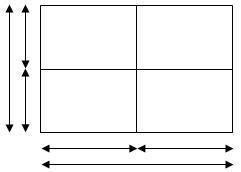
Với Interval tree thì các đoạn được chia đôi chia đôi dần. Sử dụng tư tưởng này trong Interval Tree 2D thì ta chia đôi theo cả 2D-2direction hàng và cột. Mỗi nút interval tree sẽ quản lý 1 bảng HCN nhỏ trong bảng HCN ban đầu và được chia thành 4 nút con. VD: 1 hình chữ nhật được chia làm 4 hình nhỏ hơn:
Hay nói cách khác 1 nút (x1,x2,y1,y2) có thể có tối đa 4 nút con là (x1,mx,y1,my), (x1,mx,my+1,y1), (mx+1,x2,y1,my), (mx+1,x2,my+1,y2) với mx=(x1+x2)/2;my=(y1+y2)/2.
Cây này hoàn toàn tương tự Interval tree, ta chỉ cần quản lý theo 2 chiều, có thể dùng mảng 1 chiều hoặc 2 chiều để quản lý tuỳ ý.
Áp dụng vào bài toán trên ta lưu tại mỗi nút là tổng giá trị các ô mà HCN đó quản lý.
Các hàm GET và UPDATE có thể viết hoàn toàn tương tự hàm với Interval tree, chỉ khác ở điểm từ 1 nút sẽ gọi tới 4 nút con thay vì 2. Độ phức tạp thuật toán cho các thao tác trở thành O(LogM*logN) chứ không phải là O(logN) nữa.
Cách 2: Quản lý lần lượt theo từng chiều:
Với bảng số M*N ta dùng M interval tree quản lý M hàng riêng rẽ (lớp cây T1). Tại nút (i,j) của cây lưu hàng K sẽ lưu tổng các ô từ i tới j của hàng K. Vì mỗi hàng đều có N cột nên số nút ở mỗi cây con này là bằng nhau. Giả sử có P nút con trong mỗi cây con này. Ta sử dụng lớp cây T2 gồm P cây interval nữa, mỗi cây sẽ quản lý M nút: cây thứ P sẽ quản lý nút thứ P của M cây interval trước đó. Vậy giá trị các ô trong HCN sẽ được truy xuất như thế nào? Với 1 HCN (xL,xR,yL,yR) thì đầu tiên ta tìm các nút thuộc đoạn (yL,yR) thuộc lớp cây T1. Với mỗi nút đó truy xuất dữ liệu ở cây tương ứng thuộc T2 và trong đoạn từ xL tới xR. Quá trình UPDATE dữ liệu cũng tương tự. Độ phức tạp thuật toán dạng này cũng là O(logM*logN) cho mỗi thao tác UPDATE và GET.
2 cách biểu diễn trên khác nhau nhưng có cùng độ phức tạp khi xử lý.
Yêu cầu tự viết các chương trình mô tả 2 dạng của cây Interval Tree 2D.
Bài tập tự giải:
1. CUTSEQ – Marathon 06-07.
Cho số nguyên N và một dãy số nguyên a1, a2, …, aN. Nhiệm vụ của bạn là phải cắt dãy số trên thành một
số dãy số (giữ nguyên thứ tự) thỏa mãn:
- Tổng của mỗi dãy số không lớn hơn số nguyên M.
- Tổng của các số lớn nhất trong các dãy trên là nhỏ nhất.
Input:
Dòng đầu gồm 2 số nguyên N và M.
Dòng thứ hai gồm N số nguyên của dãy a1, a2, …, aN.
Output:
Gồm một số duy nhất là tổng của các số lớn nhất trong các dãy số trên. Nếu không có cách cắt nào thỏa mãn hai điều kiện trên, in ra -1.
Giới hạn:
-1 ≤ N ≤ 100000.
-0 ≤ ai ≤ 106.
-M< 263.
2. The BUS – POI 2004.
Tóm tắt đề bài: Cho lưới ô vuông M*N. Tại K nút (giao của hàng và cột) của lưới có 1 giá trị GT>0, các nút khác giá trị bằng 0. 1 đường đi từ ô (1,1) tới ô (M,N) của lưới là đường đi thoả mãn các điều kiện sau:
- Đi theo các cạnh của lưới ô vuông, không đi theo các đường chéo.
- Chỉ có thể đi từ nút (i,j) tới nút (i+1,j) hoặc nút (i,j+1).
Giá trị của đường đi là tổng giá trị của các nút thuộc đường đi. Tìm đường đi có giá trị lớn nhất và đưa ra file output giá trị này.
Input: dòng đầu tiên ghi 3 số nguyên M N K ý nghĩa trên. K dòng tiếp theo mỗi dòng ghi 3 số X Y GT ý nghĩa là nút (X,Y) có giá trị GT.
Output: 1 dòng duy nhất ghi kết quả tìm được
Giới hạn:
-1<=M,N<=10^9.
-K<=10^5
-Kết quả trong phạm vi longint.
3. POINTS and RECTANGES
Trong mặt phẳng toạ độ cho N hình chữ nhật và M điểm. 1 điểm được gọi là thuộc 1 HCN nếu như điểm đó nằm trong phần mặt phẳng giới hạn bởi HCN đó.
Yêu cầu: liệt kê mọi điểm trong số M điểm đã cho mà thuộc ít nhất 1 HCN.
Input:
Dòng đầu ghi 2 số nguyên N M ý nghĩa như trên.
N dòng tiếp theo mỗi dòng ghi 4 số nguyên x1 y1 x2 y2 mô tả 1 HCN với đỉnh trái dưới (x1,y1) và phải trên (x2,y2).
M dòng cuối cùng ghi toạ độ M điểm đã cho
Output: Ghi ra mọi điểm thoả mãn (thứ tự bất kì).
Giới hạn: 1<=M<=N<=20000.
4.Greatest sub sequence:
Cho dãy số A gồm N phần tử (N<=50000,|Ai|<=15000). Hàm GSS của 1 đoạn [x,y] được định nghĩa như sau: GSS(x,y)=GTLN(tổng Ai..Aj), với mọi x<=i<=j<=y. VD có dãy số {-1,2,3} thì GSS(1,2)=2, GSS(1,3)=3, GSS(2,3)=5,…
Yêu cầu: tính giá trị hàm GSS của 1 số đoạn cho trước.
School@net (Theo THNT)