Hầu hết các tập tin máy tính có rất nhiều thông tin dư thừa. Các phương pháp ta đã xem xét làm tiết kiệm chỗ bằng cách khai thác một sự kiện là hầu hết các tập tin có một “nội dung thông tin” tương đối thấp. Các kỹ thuật nén tập tin thường được dùng cho các tập tin văn bản (trong đó có một số ký tự nào đó thường hơn nhiều so với các ký tự khác). Các tập tin “raster” mã hoá cho ảnh (mà nó có thể có những vùng lớn đồng nhất), và các tập tin dùng để biểu diễn âm thanh dưới dạng số hoá và các tín hiệu tương tự (analog signals) khác (các tín hiệu này có thể có các mẫu được lặp lại nhiều lần).
Ta sẽ xem một thuật toán cơ sở cho bài toán và một phương pháp “tối ưu” cấp cao. Lượng không gian được tiết kiệm bởi các phương pháp này biến thiên tuỳ thuộc vào các đặc trưng của tập tin. Tiết kiệm khoảng từ 20% đến 50% là phổ biến đối với các tập tin văn bản, và tiết kiệm khoảng từ 50% đến 90% cho các tập tin nhị phân. Đối với một vài kiểu tập tin, ví dụ như các tập tin gồm các bit ngẫu nhiên, thì lượng chỗ tiết kiệm được sẽ là ít. Các bạn sẽ thấy thú vị khi để ý là bất kỳ một phương pháp nén đa năng nào cũng sẽ làm cho một vài tập tin trở nên dài hơn (nếu không thì ta đã có thể áp dụng phương pháp đó một cách liên tục để sinh ra một tập tin nhỏ tuỳ ý).
Vậy chúng ta cần gì tới một thuật toán nén tập tin kiểu này bởi giá cả các thiết bị lưu trữ trên máy tính hiện tại không còn là vấn đề và người sử dụng có rất nhiều bộ nhớ hơn so với trước đây? Điều này sẽ phụ thuộc vào độc giả sẽ quyết định liệu có nên hay không nên bởi tại sao không khi thuật toán nhỏ này có thể giúp chúng ta thu nhỏ lại không gian bộ nhớ giúp cải thiện tối đa tốc độ máy tính của bạn!
Xây dựng mã Huffman
Các phương pháp đơn giản để thực hiện nén tập tin thường được áp dụng là MÃ HOÁ ĐỘ - DÀI - LOẠT (Run-length Encoding) và MÃ HOÁ ĐỘ DÀI BIẾN ĐỘNG (Variable- Length Encoding). Bài viết này, tôi xin đưa ra một phương pháp cùng bạn đọc hướng tới một phương pháp nén có tên Huffman.
Bước đầu tiên trong việc xây dựng mã Hufman là đếm tần số của mỗi ký tự trong thông điệp sẽ được mã hoá. Chương trình sau đây đổ vào một mảng count[0..26] các số đếm tần số cho một thông điệp trong một mảng ký tự a[l..M]. (Chương trình này dùng một thủ tục index để giữ số đếm tần số cho ký tự thứ i của bảng mẫu tự trong count[i], với count[0] được dùng cho các khoảng trống).
---
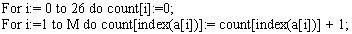
---
Ví dụ giả sử ta muốn mã hoá chuỗi
A SIMPLE STRING TO BE ENCOĐE USING A MINIMALNUMBER OF BITS.
Bảng số đếm sinh ra được minh hoạ dưới đây có 11 khoảng trống, ba chữ cái A, ba chữ B,…
Bước kế tiếp là xây dựng trie mã hoá từ dưới lên tương ứng vơiư các tần số. Trong việc xây dựng trie, ta sẽ xem nó như một cây nhị phân với các tần số được chứa trong nút: sau khi nó đã được xây dựng ta sẽ xem nó như một trie cho việc mã hoá.
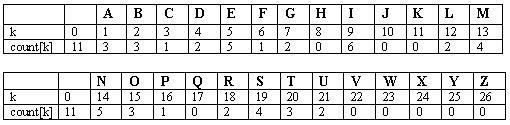
Đầu tiên một nút của cây được khởi tạo cho mỗi một tần số khác 0. Sau đó, 2 nút có tần số nhỏ nhất được tìm thấy, và một nút mới được tạo ra với hai nút con là các nút đó và với giá trị tần số là tổng các giá trị của các con (không có vấn đề là nút nào sẽ được dùng nếu như có hơn hai nút có tần số nhỏ nhất). Rồi hai nút mới với tần số nhỏ nhất trong rừng đó lại được tìm thấy, và một nút mới được tạo ra theo cùng một cách, trong hàng thứ hai bên tay trái. Tiếp tục theo cách này, ta xây dựng nên các cây con ngày càng lớn hơn và đồng thời giảm bớt giảm bớt được số cây trong rừng đi một ở mỗi bước (bớt hai thêm một). Cuối cùng, tất cả các nút được tổ hợp lại với nhau thành một cây duy nhất.
Chú ý là các nút ở trong cây mà có tần số thấp thì nằm xa gốc hơn và các nút với tần số cao sẽ nằm ở gần gốc của cây hơn. Con số dùng để đánh nhãn các nút ngoại (hình vuông) trong cây này là một số đếm tần số, trong khi con số dùng để đánh nhãn mỗi một nút nội (hình tròn) là tổng các nhãn của hai nút con của nó.
Bây giờ, mã Huffman được phát sinh một cách đơn giản bằng cách thay thế các tần số ở các nút đáy bằng các chữ cái tương ứng rồi sau đó coi cây như một trie mã hoá, với “trái” ứng với một bit mã là 0 và “phải” ứng với một bít mã là 1, đúng như ở trên. Trie cho ví dụ của chúng ta được minh hoạ trong hình dưới đây:
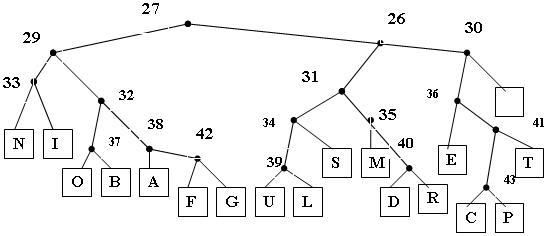
Trie mã hoá Huffman cho câu A SIMPLE STRING TO BE EN CODE…
Mã cho N là 000, mã cho I là 001, mã cho C là 110100,… Số nhỏ nằm trên mỗi nút trong cây này là chỉ mục trong mảng cout, đó là tần số được lưu trữ, dùng để tham chiếu khi ta xem xét chương trình xây dựng cây sau đây. Vì vậy, ví dụ, count[33] là 11, là tổng của các số đếm tần số cho N và I…
Rõ ràng là các chữ cái với tần số cao là gần gốc của cây hơn và được mã hoá bằng ít bit hơn, vì vậy đây là một mã tốt, nhưng tại sao nó lại là mã tốt nhất?
*** Độ dài của thông điệp được mã hoá là bằng với độ dài đường dẫn ngoại được lấy trọng (weighted external path) của cây tần số Huffman.
“Độ dài đường dẫn ngoại được lấy trọng” của một cây là tổng cuả tíhc tất cả các “trọng số”(số đếm tần số tương ứng) của các nút ngoại với khoảng cách tới gốc. Rõ ràng, đây là một cách để tính độ dài của thông điệp: Nó tương đương với tổng số lần xuất hiện trên tất cả các ký tự nhân với số bit của sự xuất hiện đó.
*** Không có cây nào với các tần số giống nhau trong các nút ngoại lại có đường dẫn ngoại được lấy trọng là nhỏ hơn cây Huffman.
Bất kỳ một cây nào cũng có thể được cấu trúc lại bởi cùng một tiến trình mà ta dùng để xây dựng cây Huffman, nhưng không cần thiết phải nhặt ra hai nút có trọng nhỏ nhất ở mỗi bước. Có thể chứng minh quy nạp là không có chiến lược nào có thể làm tốt hơn chiến lược nhặt ra hai trọng số nhỏ nhất đầu tiên.
Mô tả ở trên cung cấp một cái sườn tổng quát cách làm thế nào để mã hoá Huffman, theo thuật ngữ các thao tác thuật toán mà ta đã nghiên cứu. Như thông lệ, việc chuyển từ một mô tả tới một cài đặt thực sự là cả một quá trình, do đó ta sẽ xem xét các chi tiết của sự cài đặt ngay sau đây:
Cài đặt
Cấu trúc của cây tần số có liên quan đến tiến trình tổng quát để loại bỏ phần tử nhỏ nhất từ một tập các phần tử không được sắp thứ tự, như thế ta sẽ dùng một thủ tục
pqdownheap để xây dựng và duy trì một heap dán tiếp trên các giá trị tần số. Vì ta quan tâm đầu tiên là các giá trị nhỏ, ta sẽ giả định rằng ý nghĩa của các bất đẳng thức trong thủ tục pqdownheap đã được đảo ngược. Một thuận lợi của việc dùng tính gián tiếp này là dễ dàng bỏ qua các số đếm tần số 0.
***

***
Mô tả ví dụ (Heap khởi đầu (gián tiếp) cho việc tạo cây Huffman):
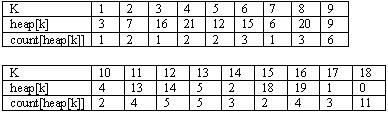
Heap được xây dựng bằng cách trước tiên khởi động mảng heap cho trỏ tới các số đếm tần số khác 0 và sau đó dùng thủ tục
qpdownheap.
***
***
Kích thước của heap được giảm đi một. Sau đó một nút nội mới được “khởi tạo” với chỉ mục 26+N và được cho một giá trị bằng với tổng của giá trị nằm ở gốc với giá trị vừa được loại ra. Sau đó mã này được đặt ở gốc, do đó tăng độ ưu tiên của nó lên, vì vậy cần đến một lệnh gọi khác với qpdownheap để phục hồi lại trật tự trong heap. Bản thân cây được biểu diễn bởi một mảng các liên kết “cho con”: dad[t] là chỉ mục của cha của nút mà trọng số của nó ở trong count[t]. Dấu của dad[t] chỉ ra khi nào nút là con trái hay con phải của nút cha của nó. Ví dụ, trong cây ở trên ta có count[30]=21, dad[30]= -28, và count[28]= 37 (chỉ ra nút có trọng 21 sẽ có chỉ mục là 30 và đó là con phải của một cha có chỉ mục 28 và trọng 37). Hình dưới đây sẽ cho thấy mảng dad cho các nút nội của cây trong ví dụ của chúng ta.
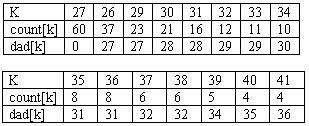 Biểu diễn mối liên kết cha con của cây Huffman
Biểu diễn mối liên kết cha con của cây Huffman
***

***
Cuối cùng, ta có thể dùng các biểu diễn của mã đã được tính này để mã hoá thông điệp:
***

***
Chương trình này dùng thủ tục bits để truy xuất các bit đơn lẻ. Thông điệp mẫu của chúng ta được mã hoá chỉ trong 236 bits so với 300 bits được dùng cho việc mã hoá đơn giản, tiết kiệm khoảng 21%.
Bây giờ, như đã đề cập ở trên, cây phải được cất hay gửi đi cùng thông điệp để giải mã nó. May thay, điều này chứa một mảng code, vì trie tìm kiếm theo cơ số, phát sinh từ việc chèn các đầu vào của mảng đó trong một cây rỗng khởi đầu chính là cây giải mã.
Vì vậy việc tiết kiệm bộ nhớ đã được dẫn chứng ở trên là không hoàn toàn chính xác, vì thông điệp không thể được giải mã mà không có trie và ta phải kết toán phí tổn lưu trie cùng với thông điệp. Mã hoá Huffman vì vậy chỉ có hiệu quả đối với các tập tin dài ở đó việc tiết kiệm trong thông điệp là đủ để đền bù lại các phí tổn, hay trong các trường hợp ở đó trie mã hoá có thể được tính toán trước và được dùng cho một số lượng lớn các thông điệp. Ví dụ, một trie dựa trên tần số xuất hiện của các chữ cái trong tiếng Anh có thể được dùng cho các tài liệu văn bản. Đối với các chương trình Pascal có thể được dùng cho các chương trình mã hoá. Một thuật toán Hufman tiết kiệm khoảng 23% khi thực hiện trên văn bản.



